Handling whitespace
Sự hiện diện của khoảng trắng trong DOM có thể gây ra vấn đề bố cục và làm cho việc thao tác với cây nội dung trở nên khó khăn theo những cách bất ngờ, tùy thuộc vào vị trí của nó. Bài viết này khám phá những khó khăn có thể xảy ra và xem xét những gì có thể được thực hiện để giảm thiểu các vấn đề phát sinh.
Khoảng trắng là gì?
Các ký tự Whitespace bao gồm các ký tự khác nhau trong các ngữ cảnh ngôn ngữ lập trình khác nhau. Document white space characters, theo các quy tắc xử lý khoảng trắng CSS, chỉ bao gồm dấu cách (U+0020), tab (U+0009), line feed (LF, U+000A), và carriage return (CR, U+000D), trong đó các ký tự CR tương đương với dấu cách theo mọi cách. Các ký tự này cho phép bạn định dạng code để dễ đọc hơn. Phần lớn source code của chúng ta chứa đầy các ký tự khoảng trắng này, và chúng ta thường chỉ xóa chúng như một phần của bước build production để giảm kích thước file.
Lưu ý rằng danh sách này không bao gồm non-breaking space (U+00A0, trong HTML). Vì vậy các ký tự này không kích hoạt bất kỳ collapsing nào, đó là lý do tại sao chúng thường được sử dụng để tạo các khoảng cách dài hơn trong HTML.
CSS cũng định nghĩa khái niệm segment break, trong bối cảnh HTML tương đương với các ký tự LF.
HTML xử lý khoảng trắng như thế nào?
Đây là một quan niệm sai lầm phổ biến rằng "HTML bỏ qua khoảng trắng", điều đó không đúng: HTML giữ lại tất cả nội dung văn bản khoảng trắng như bạn đã viết trong source code. Là một ngôn ngữ đánh dấu, HTML tạo ra một DOM trong đó tất cả khoảng trắng trong nội dung văn bản được giữ lại, có thể được lấy và thao tác thông qua các API DOM như Node.textContent. Nếu HTML loại bỏ khoảng trắng khỏi DOM, thì CSS, một rendering engine downstream hoạt động trên DOM, sẽ không thể giữ lại chúng bằng thuộc tính white-space.
Note: Để rõ ràng, chúng ta đang nói về khoảng trắng giữa các HTML tag, trở thành text node trong DOM. Bất kỳ khoảng trắng nào bên trong một tag (giữa các dấu ngoặc nhọn nhưng không phải là một phần của giá trị thuộc tính) chỉ là một phần của cú pháp HTML và không xuất hiện trong DOM.
Note:
Do phép màu của việc phân tích HTML (trích dẫn từ DOM spec), có những nơi nhất định mà các ký tự khoảng trắng có thể bị bỏ qua. Ví dụ, khoảng trắng giữa thẻ <html> và <head> mở hoặc giữa thẻ </body> và </html> đóng bị bỏ qua và không xuất hiện trong DOM. Ngoài ra, khi phân tích nội dung văn bản của phần tử <pre>, một ký tự newline đầu dòng sẽ bị xóa. Chúng ta bỏ qua những trường hợp ngoại lệ này.
Hơn nữa, HTML parser chuẩn hóa một số khoảng trắng nhất định: nó thay thế các chuỗi CR và CRLF bằng một LF đơn. Tuy nhiên, các ký tự CR cũng có thể được chèn vào DOM thông qua tham chiếu ký tự hoặc JavaScript, vì vậy các quy tắc xử lý khoảng trắng CSS vẫn cần định nghĩa cách xử lý chúng.
Ví dụ, hãy lấy tài liệu sau:
<!doctype html>
<html lang="vi">
<head>
<meta charset="UTF-8" />
<title>My Document</title>
</head>
<body>
<h1>Header</h1>
<p>Paragraph</p>
</body>
</html>
Cây DOM cho tài liệu này trông như sau:

Lưu ý rằng:
- Một số text node chỉ chứa khoảng trắng.
- Các text node khác có thể có khoảng trắng ở đầu hoặc cuối.
Note: Firefox DevTools hỗ trợ highlight các text node, cho phép bạn thấy chính xác những node nào chứa ký tự khoảng trắng. Các node khoảng trắng thuần túy được đánh dấu bằng nhãn "whitespace".
Giữ lại các ký tự khoảng trắng trong DOM rất hữu ích theo nhiều cách, nhưng nó cũng có thể làm cho một số bố cục khó thực hiện hơn và có thể gây ra vấn đề cho các nhà phát triển muốn lặp qua các DOM node. Chúng ta sẽ xem xét những vấn đề này và một số giải pháp sau trong phần giải quyết các vấn đề phổ biến với whitespace node.
CSS xử lý khoảng trắng như thế nào?
Khi DOM được truyền cho CSS để hiển thị, khoảng trắng phần lớn bị loại bỏ theo mặc định. Điều này có nghĩa là cách bạn định dạng code không hiển thị với người dùng cuối — việc tạo khoảng cách xung quanh và bên trong các phần tử là nhiệm vụ của CSS.
<!doctype html>
<h1> Hello World! </h1>
Source code này chứa một vài line feed sau doctype và một loạt ký tự dấu cách trước, sau và bên trong phần tử <h1>. Nhưng trình duyệt bỏ qua các khoảng trắng này và chỉ hiển thị các từ "Hello World!" như thể các ký tự này không tồn tại:
CSS bỏ qua hầu hết, nhưng không phải tất cả, các ký tự khoảng trắng. Trong ví dụ này, một trong các dấu cách giữa "Hello" và "World!" vẫn tồn tại khi trang được hiển thị trong trình duyệt. CSS sử dụng một thuật toán cụ thể để quyết định ký tự khoảng trắng nào không liên quan đến người dùng và cách chúng bị xóa hoặc chuyển đổi. Chúng ta sẽ giải thích cách xử lý này hoạt động trong các phần tiếp theo.
Collapsing và transformation
Hãy xem một ví dụ. Để làm cho các ký tự khoảng trắng dễ thấy hơn, chúng ta cũng đã thêm một comment để hiển thị tất cả các dấu cách là ◦, tất cả tab là ⇥, và tất cả line break là ⏎:
<h1> Hello
<span> World!</span> </h1>
<!--
<h1>◦◦◦Hello◦⏎
⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>
-->
Ví dụ này được hiển thị trong trình duyệt như sau:
Phần tử <h1> chứa:
- Một text node (bao gồm một số dấu cách, từ "Hello", một line break, và một số tab).
- Một inline element (
<span>, chứa một dấu cách và từ "World!"). - Một text node khác (với một tab và dấu cách sau
<span>).
Vì phần tử <h1> này chỉ chứa các inline element, nó thiết lập một inline formatting context. Đây là một trong số các ngữ cảnh hiển thị bố cục mà browser engine sử dụng để sắp xếp nội dung trên trang.
Trong inline formatting context này, các ký tự khoảng trắng được xử lý như sau:
Note:
Thuật toán này có thể được cấu hình thông qua thuộc tính white-space-collapse (hoặc thuộc tính shorthand white-space). Chúng ta sẽ bắt đầu bằng cách giả định giá trị mặc định của nó (white-space-collapse: collapse), sau đó xem xét cách các giá trị thuộc tính khác nhau ảnh hưởng đến thuật toán này.
-
Đầu tiên, tất cả các dấu cách và tab ngay trước và sau một line break bị bỏ qua. Vì vậy, nếu chúng ta lấy ví dụ markup trước đó:
html<h1>◦◦◦Hello◦⏎ ⇥⇥⇥⇥<span>◦World!</span>⇥◦◦</h1>...và áp dụng quy tắc đầu tiên này, chúng ta nhận được:
html<h1>◦◦◦Hello⏎ <span>◦World!</span>⇥◦◦</h1> -
Tiếp theo, các line break liên tiếp được rút gọn thành một line break đơn. Chúng ta không có trường hợp này trong ví dụ.
-
Tiếp theo, các dòng trong source code được nối thành các dòng đơn bằng cách xóa bất kỳ ký tự line break còn lại nào. Chúng hoặc được chuyển đổi thành dấu cách (U+0020) hoặc đơn giản là bị xóa, tùy thuộc vào ngữ cảnh trước và sau break. Lựa chọn chính xác giữa hai là phụ thuộc vào trình duyệt và ngôn ngữ. Trong ví dụ tiếng Anh ở đây (nơi dấu cách phân tách các từ), chúng ta có thể mong đợi tất cả line break được "chuyển đổi" thành dấu cách. Vì vậy chúng ta kết thúc với:
html<h1>◦◦◦Hello◦<span>◦World!</span>⇥◦◦</h1>Đáng chú ý, trong các ngôn ngữ không có dấu phân tách từ, như tiếng Trung, các dòng được nối mà không có khoảng cách xen vào. Vì vậy:
html<div>你好 世界</div>có thể được hiển thị là "你好世界" không có dấu cách ở giữa, tùy thuộc vào heuristic của trình duyệt.
-
Tiếp theo, tất cả ký tự tab được chuyển đổi thành ký tự dấu cách, vì vậy ví dụ trở thành:
html<h1>◦◦◦Hello◦<span>◦World!</span>◦◦◦</h1> -
Sau đó, bất kỳ dấu cách nào ngay sau một dấu cách khác (thậm chí qua hai inline element riêng biệt) bị bỏ qua, vì vậy chúng ta kết thúc với:
html<h1>◦Hello◦<span>World!</span>◦</h1>
Đó là lý do tại sao những người truy cập trang web sẽ thấy cụm từ "Hello World!" được viết gọn gàng ở đầu trang, thay vì một "Hello" thụt lề kỳ lạ theo sau bởi một "World!" thụt lề còn kỳ lạ hơn trên dòng tiếp theo.
Sau các bước này, trình duyệt xử lý việc ngắt dòng và văn bản hai chiều, chúng ta sẽ bỏ qua ở đây. Lưu ý rằng vẫn còn dấu cách sau thẻ <h1> mở và trước thẻ </h1> đóng, nhưng những dấu cách này không được hiển thị trong trình duyệt. Chúng ta sẽ xử lý điều đó tiếp theo, khi mỗi dòng được bố cục.
Các giá trị white-space-collapse khác nhau bỏ qua các bước khác nhau của thuật toán này:
preservevàbreak-spaces: toàn bộ thuật toán bị bỏ qua và không có collapsing hoặc transformation khoảng trắng nào xảy ra.preserve-breaks: các bước 2 và 3 bị bỏ qua và line break được giữ lại.preserve-spaces: toàn bộ thuật toán bị bỏ qua và được thay thế bằng một bước duy nhất để chuyển đổi mỗi tab hoặc line break thành dấu cách.
Tóm lại, các ký tự khoảng trắng khác nhau được rút gọn và chuyển đổi theo cách sau:
- Tab thường được chuyển đổi thành dấu cách.
- Nếu các segment break cần được rút gọn:
- Các chuỗi segment break được rút gọn thành một segment break đơn.
- Chúng được chuyển đổi thành dấu cách trong các ngôn ngữ phân tách từ bằng dấu cách (như tiếng Anh), hoặc bị xóa hoàn toàn trong các ngôn ngữ không phân tách từ bằng dấu cách (như tiếng Trung).
- Nếu các dấu cách cần được rút gọn:
- Các dấu cách hoặc tab trước hoặc sau các segment break bị xóa.
- Các chuỗi dấu cách được rút gọn thành một dấu cách đơn.
- Khi các dấu cách được giữ lại, các chuỗi dấu cách được coi là non-breaking, ngoại trừ chúng sẽ soft wrap ở cuối mỗi chuỗi — tức là dòng tiếp theo sẽ luôn bắt đầu bằng ký tự không phải dấu cách tiếp theo. Tuy nhiên, trong trường hợp giá trị
break-spaces, một soft wrap có thể xảy ra sau mỗi dấu cách, vì vậy dòng tiếp theo có thể bắt đầu bằng một hoặc nhiều dấu cách.
Trimming và positioning
Trong cả hai ngữ cảnh định dạng inline và block, các phần tử được bố cục theo các dòng. Trong inline formatting context, các dòng được tạo bởi text wrapping. Trong block formatting context, mặt khác, mỗi block tạo thành dòng riêng của nó. Khi mỗi dòng được bố cục, khoảng trắng được xử lý thêm. Hãy xem một ví dụ để giải thích cách điều này hoạt động.
Trong ví dụ này, như trước đây, chúng ta đã đánh dấu các ký tự khoảng trắng trong một comment. Chúng ta có ba text node chỉ chứa khoảng trắng: một trước <div> đầu tiên, một giữa hai <div>, và một sau <div> thứ hai.
<body>
<div> Hello </div>
<div> World! </div>
</body>
<!--
<body>⏎
⇥<div>⇥Hello⇥</div>⏎
⏎
◦◦◦<div>◦◦World!◦◦</div>◦◦⏎
</body>
-->
Kết quả hiển thị như sau:
Khoảng trắng trong ví dụ này được xử lý như sau:
Note:
Thuật toán này có thể được cấu hình thông qua thuộc tính white-space-collapse (hoặc thuộc tính shorthand white-space). Chúng ta sẽ bắt đầu bằng cách giả định giá trị mặc định của nó (white-space-collapse: collapse), sau đó xem xét cách các giá trị thuộc tính khác nhau ảnh hưởng đến thuật toán này.
-
Đầu tiên, khoảng trắng được rút gọn theo cùng cách như chúng ta đã thấy trong phần trước, biến điều này:
html<body>⏎ ⇥<div>⇥Hello⇥</div>⏎ ⏎ ◦◦◦<div>◦◦World!◦◦</div>◦◦⏎ </body>...thành điều này:
html<body>◦<div>◦Hello◦</div>◦<div>◦World!◦</div>◦</body>Sau đó các dòng được bố cục theo block formatting context được thiết lập bởi
<body>. Trong ví dụ này, mỗi trong số năm child node của<body>được bố cục như một dòng riêng biệt. (Mỗi dòng trong code block này đại diện cho một dòng trong bố cục được hiển thị, không phải một dòng trong HTML gốc của chúng ta):html<body> ◦ <div>◦Hello◦</div> ◦ <div>◦World!◦</div> ◦ </body>Lưu ý rằng nếu các dòng quá dài, mỗi dòng có thể wrap và tạo ra nhiều dòng hơn. Trên thực tế, trình duyệt xác định nội dung của các dòng khi chúng được bố cục. Chúng ta sẽ bỏ qua phần về cách text wrapping hoạt động.
-
Các chuỗi dấu cách ở đầu dòng bị xóa, vì vậy ví dụ trở thành:
html<body> <div>Hello◦</div> <div>World!◦</div> </body> -
Mỗi tab được giữ lại ở điểm này được hiển thị theo
tab-size. Điều này chỉ có thể xảy ra vớiwhite-space-collapseđược đặt thànhpreservehoặcbreak-spacesvì tất cả các cài đặt khác biến tab thành dấu cách. -
Các chuỗi dấu cách ở cuối dòng bị xóa, vì vậy trên đây trở thành:
html<body> <div>Hello</div> <div>World!</div> </body>
Ba dòng trống chúng ta có bây giờ sẽ không chiếm bất kỳ không gian nào trong bố cục cuối cùng, vì chúng không chứa bất kỳ nội dung hiển thị nào. Vì vậy chúng ta sẽ kết thúc chỉ với hai dòng chiếm không gian trong trang. Những người xem trang web sẽ thấy các từ "Hello" và "World!" trên hai dòng riêng biệt, đúng như bạn mong đợi hai <div> được bố cục. Trình duyệt về cơ bản bỏ qua tất cả khoảng trắng đã được bao gồm trong code HTML.
Các giá trị white-space-collapse khác nhau bỏ qua các bước khác nhau của thuật toán này:
preservevàbreak-spaces: Toàn bộ thuật toán bị bỏ qua ngoại trừ bước 3, vì vậy không có collapsing hoặc transformation khoảng trắng nào xảy ra.preserve-spaces: Toàn bộ thuật toán bị bỏ qua, vì vậy các ký tự khoảng trắng ở đầu và cuối dòng được giữ lại.preserve-breaks: Thuật toán tương tự được áp dụng như với giá trịcollapse.
Các DOM API xử lý khoảng trắng như thế nào?
Như đã đề cập trước đây, khoảng trắng được giữ lại trong DOM. Điều này có nghĩa là nếu bạn lấy Node.textContent, bạn sẽ nhận được nội dung văn bản như bạn đã viết nó trong HTML source code, và nếu bạn lấy Node.childNodes, bạn sẽ nhận được tất cả text node, bao gồm cả những text node chỉ chứa khoảng trắng.
Không phải tất cả các DOM API đều giữ lại khoảng trắng; một số API xử lý rendered text theo thiết kế. Ví dụ, HTMLElement.innerText trả về văn bản chính xác như nó được hiển thị, với tất cả khoảng trắng được rút gọn và cắt bỏ. Selection.toString() trả về văn bản như nó sẽ được dán, thường có nghĩa là khoảng trắng được rút gọn. Tuy nhiên, trong Firefox (rút gọn khoảng trắng giữa các ký tự Trung Quốc, như đã đề cập trong phần collapsing và transformation ở trên), khoảng trắng được rút gọn vẫn được giữ lại cả trong chuỗi được trả về bởi toString() và trong văn bản được dán.
<div id="test">Hello world!</div>
const div = document.getElementById("test");
console.log(div.textContent); // " Hello\n world!\n"
console.log(div.innerText); // "Hello world!"
const selection = document.getSelection();
selection.selectAllChildren(div);
console.log(selection.toString()); // "Hello world!"
Giải quyết các vấn đề phổ biến với whitespace node
Các whitespace node vô hình với người truy cập trang web do các quy tắc xử lý CSS, nhưng chúng có thể can thiệp vào một số bố cục và thao tác DOM dựa trên cấu trúc chính xác của DOM. Hãy xem một số vấn đề phổ biến và cách giải quyết chúng.
Xử lý khoảng trắng giữa các phần tử inline và inline-block
Hãy xem xét một vấn đề bố cục với whitespace node: khoảng cách giữa các phần tử inline và inline-block. Như chúng ta đã thấy trước đó với các phần tử inline và block, hầu hết các ký tự khoảng trắng bị bỏ qua, nhưng các ký tự phân tách từ như dấu cách vẫn còn lại. Khoảng trắng thêm đó đến được bố cục rất hữu ích để phân tách các từ trong câu.
Với các phần tử inline-block, nó trở nên thú vị hơn: các phần tử này hoạt động như các inline element từ bên ngoài và block từ bên trong. (Chúng thường được sử dụng để hiển thị các phần UI phức tạp hơn, đặt cạnh nhau trên cùng một dòng, chẳng hạn như các mục menu điều hướng.) Bất kỳ khoảng trắng nào giữa các phần tử inline hoặc inline-block liền kề sẽ dẫn đến khoảng cách trong bố cục, giống như khoảng cách giữa các từ trong văn bản. (Điều này có thể làm nhà phát triển ngạc nhiên vì chúng là block, và block thường không hiển thị khoảng cách thêm.)
Hãy xem xét ví dụ này (như trước đây, chúng ta đã bao gồm một comment trong code HTML để hiển thị các ký tự khoảng trắng):
.people-list {
list-style-type: none;
margin: 0;
padding: 0;
}
.people-list li {
display: inline-block;
width: 2em;
height: 2em;
background: #ff0066;
border: 1px solid;
}
<ul class="people-list">
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul>
<!--
<ul class="people-list">⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
⏎
◦◦<li></li>⏎
</ul>
-->
Kết quả hiển thị như sau:
Bạn có thể không muốn khoảng cách giữa các block. Tùy thuộc vào trường hợp sử dụng của bạn (chẳng hạn như danh sách avatar hoặc hàng nút điều hướng ngang), bạn có thể muốn các phần tử tiếp xúc nhau và có thể tự kiểm soát bất kỳ khoảng cách nào.
Firefox DevTools HTML Inspector có thể highlight các text node và cũng cho bạn thấy chính xác diện tích các phần tử chiếm. Điều này rất hữu ích để kiểm tra xem có margin thêm hay khoảng trắng bất ngờ gây ra khoảng cách hay không.
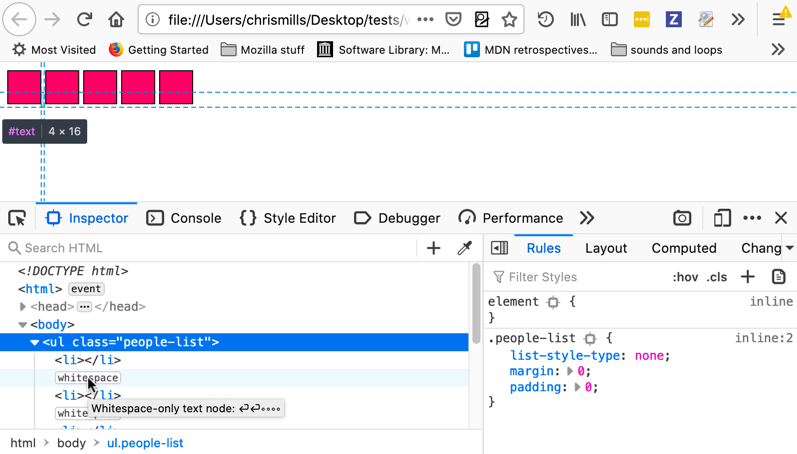
Có một vài cách để giải quyết vấn đề này:
-
Sử dụng Flexbox để tạo danh sách ngang của các mục thay vì thử giải pháp
inline-block. Flexbox xử lý khoảng cách và căn chỉnh cho bạn, và chắc chắn là giải pháp ưa thích:cssul { list-style-type: none; margin: 0; padding: 0; display: flex; } -
Nếu bạn cần dựa vào
inline-block, bạn có thể đặtfont-sizecủa danh sách thành0. Điều này chỉ hoạt động nếu các block không được định kích thước bằng đơn vịem(vìemdựa trênfont-size, kích thước block cũng sẽ được định kích thước là0). Sử dụng đơn vịremsẽ là lựa chọn tốt ở đây:cssul { font-size: 0; /* … */ } li { display: inline-block; width: 2rem; height: 2rem; /* … */ } -
Ngoài ra, bạn có thể đặt margin âm trên các mục danh sách:
cssli { display: inline-block; width: 2rem; height: 2rem; margin-right: -0.25rem; } -
Bạn cũng có thể giải quyết vấn đề này bằng cách tránh các whitespace node giữa các mục
<li>:html<li> ... </li><li> ... </li>
Làm việc với khoảng trắng trong DOM
Như đã đề cập trước đây, khoảng trắng được rút gọn và cắt bỏ khi được hiển thị, nhưng được giữ lại trong DOM. Điều này có thể gây ra một số vấn đề khi cố gắng thực hiện thao tác DOM trong JavaScript. Ví dụ, nếu bạn có tham chiếu đến một node cha và muốn thao tác với phần tử con đầu tiên của nó bằng cách sử dụng Node.firstChild, một whitespace node ngay sau thẻ cha mở sẽ cho bạn kết quả sai. Text node sẽ được chọn thay vì phần tử bạn muốn nhắm đến.
Như một ví dụ khác, nếu bạn muốn làm điều gì đó với một tập hợp con của các phần tử dựa trên việc chúng có rỗng không (không có child node), bạn có thể sử dụng Node.hasChildNodes(). Nhưng nếu bất kỳ phần tử nào trong số đó chứa text node, bạn có thể nhận được kết quả sai.
Code JavaScript sau đây hiển thị một số hàm xử lý khoảng trắng trong DOM:
/**
* Throughout, whitespace is defined as one of the characters
* "\t" TAB \u0009
* "\n" LF \u000A
* "\r" CR \u000D
* " " SPC \u0020
*
* This does not use JavaScript's "\s" because that includes non-breaking
* spaces (and also some other characters).
*/
/**
* Determine whether a node's text content is entirely whitespace.
*
* @param nod A node implementing the `CharacterData` interface (i.e.,
* a `Text`, `Comment`, or `CDATASection` node)
* @return `true` if all of the text content of `nod` is whitespace,
* otherwise `false`.
*/
function isAllWs(nod) {
return !/[^\t\n\r ]/.test(nod.textContent);
}
/**
* Determine if a node should be ignored by the iterator functions.
*
* @param nod An object implementing the `Node` interface.
* @return `true` if the node is:
* 1) A `Text` node that is all whitespace
* 2) A `Comment` node
* and otherwise `false`.
*/
function isIgnorable(nod) {
return (
nod.nodeType === 8 || // a comment node
(nod.nodeType === 3 && isAllWs(nod))
); // a text node, all ws
}
/**
* Version of `previousSibling` that skips nodes that are entirely
* whitespace or comments. (Normally `previousSibling` is a property
* of all DOM nodes that gives the sibling node, the node that is
* a child of the same parent, that occurs immediately before the
* reference node.)
*
* @param sib The reference node.
* @return The closest previous sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null` if
* no such node exists.
*/
function nodeBefore(sib) {
while ((sib = sib.previousSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `nextSibling` that skips nodes that are entirely
* whitespace or comments.
*
* @param sib The reference node.
* @return The closest next sibling to `sib` that is not
* ignorable according to `isIgnorable`, or `null`
* if no such node exists.
*/
function nodeAfter(sib) {
while ((sib = sib.nextSibling)) {
if (!isIgnorable(sib)) {
return sib;
}
}
return null;
}
/**
* Version of `lastChild` that skips nodes that are entirely
* whitespace or comments. (Normally `lastChild` is a property
* of all DOM nodes that gives the last of the nodes contained
* directly in the reference node.)
*
* @param sib The reference node.
* @return The last child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function lastChild(par) {
let res = par.lastChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.previousSibling;
}
return null;
}
/**
* Version of `firstChild` that skips nodes that are entirely
* whitespace and comments.
*
* @param sib The reference node.
* @return The first child of `sib` that is not ignorable
* according to `isIgnorable`, or `null` if no
* such node exists.
*/
function firstChild(par) {
let res = par.firstChild;
while (res) {
if (!isIgnorable(res)) {
return res;
}
res = res.nextSibling;
}
return null;
}
/**
* Version of `data` that doesn't include whitespace at the beginning
* and end and normalizes all whitespace to a single space. (Normally
* `data` is a property of text nodes that gives the text of the node.)
*
* @param txt The text node whose data should be returned
* @return A string giving the contents of the text node with
* whitespace collapsed.
*/
function dataOf(txt) {
let data = txt.textContent;
data = data.replace(/[\t\n\r ]+/g, " ");
if (data[0] === " ") {
data = data.substring(1, data.length);
}
if (data[data.length - 1] === " ") {
data = data.substring(0, data.length - 1);
}
return data;
}
Code sau đây minh họa việc sử dụng các hàm ở trên. Nó lặp qua các con của một phần tử (có con là tất cả các phần tử) để tìm cái có văn bản là "This is the third paragraph", sau đó thay đổi thuộc tính class và nội dung của đoạn đó.
let cur = firstChild(document.getElementById("test"));
while (cur) {
if (dataOf(cur.firstChild) === "This is the third paragraph.") {
cur.className = "magic";
cur.firstChild.textContent = "This is the magic paragraph.";
}
cur = nodeAfter(cur);
}